从GPU内存墙到硅片革命:ModelBased架构如何撕开千倍效率突破口
2012年的GTC大会上,黄仁勋展示TeslaK20时,我正坐在斯坦福EE系实验室里盯着示波器发呆。那时的AI计算还是小众游戏,没人能想到十二年后,一家加拿大初创公司会用"把模型焊死在硅片上"的激进路线,在英伟达的护城河上炸开一道口子。
内存墙困局:通用GPU的原罪
传统AI芯片的设计哲学可以概括为三个字:兼容性。为了跑通TensorFlow、PyTorch、JAX无数框架,为了支持VGG、ResNet、Transformer各种架构,GPU必须预留大量运算单元与调度逻辑。这种"万金油"设计在训练阶段无可厚非,但到了推理阶段就成了巨大的资源浪费。
数据不会说谎。HBM3内存带宽顶着1.6TB/s的恐怖数字,实际推理时有效利用率往往不足30%。芯片上密密麻麻的晶体管,有相当比例在推理时处于"假寐"状态。这就是摩尔定律在AI时代遭遇的诡异悖论:算力在增长,效率却在下降。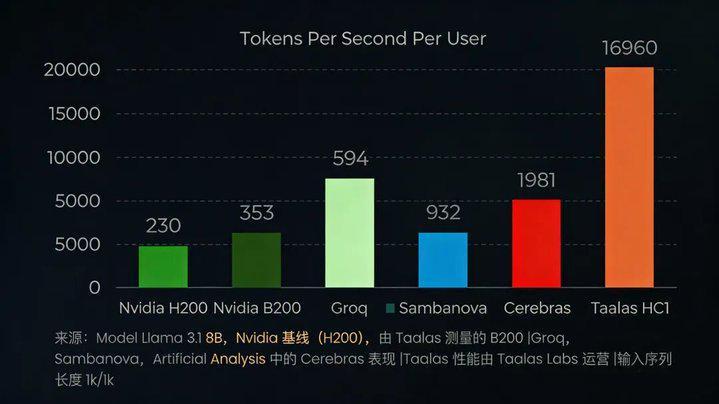
巴伊奇的破局思路:硬件即模型
LjubisaBajic在Tenstorrent主导过可扩展AI加速器研发,深知通用架构的局限性。2023年3月离职后,他找到DragoIgnjatovic和LejlaBajic,三个人在多伦多一间小办公室里开始了一场"反通用"实验。
核心理念简单到近乎粗暴:既然推理时模型权重是固定的,为什么不把它固化到硬件层面?不需要HBM,不需要复杂的调度器,只需要针对特定模型的计算图进行电路级优化。maskROMrecallfabric+SRAM架构,就这样被塞进了HC1芯片里。
硬连线设计的工程代价
代价是明显的。定点数格式无法满足复杂推理的精度需求,简单运算出现错误、复杂问题出现"幻觉",这些问题在HC1上真实存在。但巴伊奇选择了一条务实的路线:先用极致速度打开市场,再用HC2的4-bit浮点格式改善精度。
24人团队、3000万美元研发成本、2个月从权重到硬件的交付周期。这些数字在芯片行业堪称变态效率,背后的代价是放弃一切"通用性幻想"。Taalas赌的是:大模型架构演进速度会放缓,Llama等开源模型会占据主导地位,专用芯片的市场窗口足够长。
商业路径的三条轨道
目前Taalas的商业化布局清晰可见:自建API切入云服务市场、直接出售HC1芯片给企业客户、与模型开发商合作定制化芯片。三条轨道指向同一个目标——锁定高粘性的垂直场景。
金融、医疗、法律行业的私有化部署是HC1的天然适配场景。这些客户常年运行固定版本模型,对延迟敏感,对成本敏感。0.75美分/百万token的推理成本,对比传统GPU云服务的2美元,这个266倍的差距足以让许多此前不可行的AI应用重新具备商业价值。
生态构建才是终极壁垒
英伟达的护城河从来不是硬件。CUDA生态、开发者社区、行业标准制定权——这些软实力比任何芯片架构都难复制。Taalas目前的短板正在于此:没有开发工具链,没有配套SDK,开发者需要完全重新适配。
但历史告诉我们,生态壁垒的建立往往始于一款现象级产品。HC1的速度优势已经引发行业关注,Basecamp创始人DHH的"感觉像作弊一样快"评价,正在社交网络持续发酵。当足够多的开发者开始使用专用芯片,当垂直场景的应用案例积累到临界点,生态自然会生长。
推理时代的算力新格局
英伟达200亿美元收购Groq推理技术许可,是这场变局的最佳注脚。通用算力巨头正在用资本手段快速补全专用推理短板,而Groq的LPU架构与Taalas的ModelBased路线正在形成某种技术收敛:减少内存访问、提升片上计算密度、用确定性设计替代动态调度。
未来的AI算力市场不会只有一种声音。英伟达GPU主导训练和通用推理,专用芯片占据高价值垂直场景,云厂商自研芯片深耕云原生市场。三分天下的格局正在形成,而Taalas正在证明:效率革命有时候需要的是勇气,而不是妥协。