从康威生命游戏到语言模型:细胞自动机预训练的深层逻辑与技术突破
2019年深秋,我第一次在屏幕上看到康威生命游戏的演化轨迹时,完全没想到它会在五年后成为大语言模型预训练的关键素材。当时我只觉得这个1970年的数学玩具很神奇——几条简单规则,就能涌现出滑翔机、脉冲枪,甚至能模拟图灵机的复杂结构。
缘起:复杂性科学的一次意外跨界
生命游戏的核心设定极其精炼:每个方格非生即死,活细胞邻居太少会孤独而死,太多会因拥挤而亡,死细胞恰好有三个活邻居就会复活。没有人操控,没有外部干预,这些简单规则在无限延伸的棋盘上自行演化,生成无穷复杂的行为。半个多世纪以来,这被视为复杂性科学的经典演示。
MITImprobableAI实验室的PulkitAgrawal团队在2025年3月发表的论文,提出了一个听起来不合常理的想法:用类似生命游戏的细胞自动机生成的数据,去预训练大型语言模型。这些数据不包含任何文字、任何语义,只是一个12×12网格上像素不断演化的轨迹。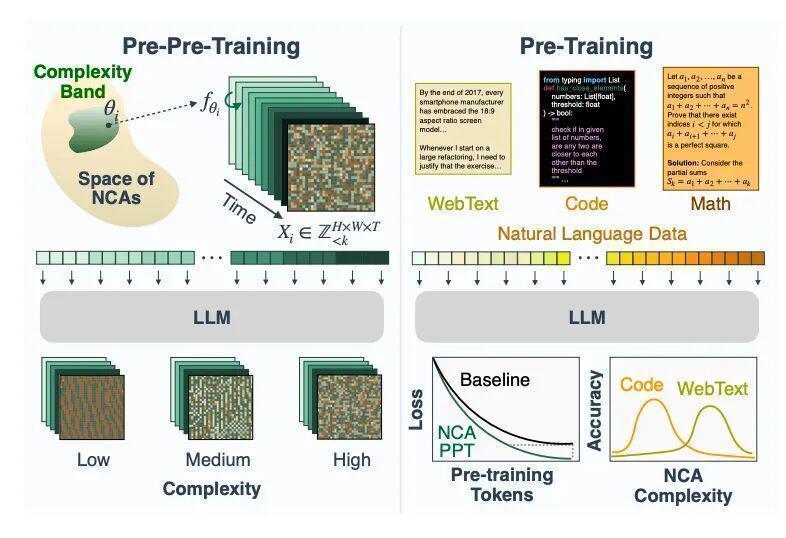
数据:合成轨迹的惊人效果
实验结果超出所有人预期。在这些纯粹的动态图案上训练过的模型,在随后自然语言学习中的困惑度降低了最多6%,收敛速度加快了最多1.6倍。更让人意外的是,仅用1.64亿个细胞自动机token做预训练,效果竟然超过用16亿个真实英语文本(来自CommonCrawl数据集C4)做同样预训练。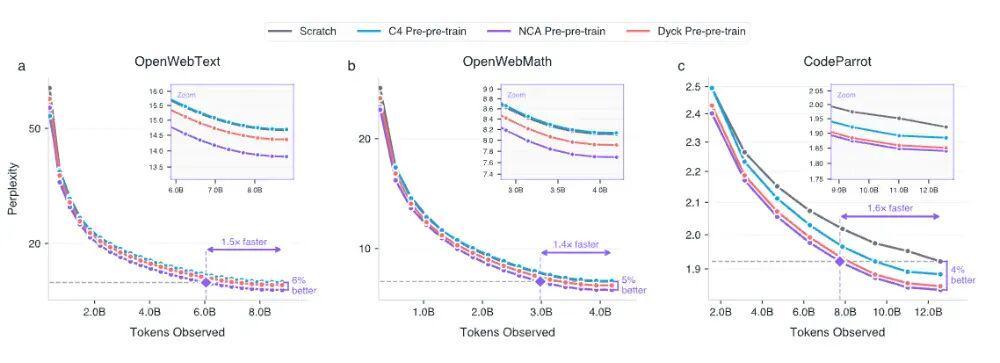
研究者使用的是神经细胞自动机(NCA),这是经典细胞自动机的推广版本。传统细胞自动机使用固定规则,而NCA把规则替换成一个小型神经网络——具体来说是一个3×3卷积加上一层MLP。每次生成训练数据时,研究者随机初始化这个网络的权重,等于随机抽取一条全新的动力学规则,然后让它在网格上跑出一段时空演化轨迹。
原理:从语言到计算结构的范式转移
这些轨迹被切割成2×2的图像块,映射为token序列,再用标准的下一个token预测任务来训练transformer。模型拿到的每一条序列,都来自一个它从未见过的规则。要预测下一个token,它必须在上下文中推断出这条隐藏规则,然后应用它。这和语言模型在真实文本上做的事情存在深层对应。
斯坦福大学马腾宇与PercyLiang团队在2022年的工作中论证过,下一个token预测本质上是一种隐式的贝叶斯推断:模型从已有文本中推断出潜在的生成概念,再据此预测接下来会出现什么。NCA训练把这个过程提纯了。
自然语言中混杂着语义快捷方式和共现先验,模型可以投机取巧;而NCA数据中没有任何语义可以依赖,每一个token都在迫使模型做纯粹的规则推断。这套方法被称为pre-pre-training,即在正式语言预训练之前,先用合成数据做一轮预预训练。
实验:可量化的性能提升
训练流程分三步走:先在NCA数据上训练transformer的非嵌入层权重,再在自然语言语料上做标准预训练,最后是针对具体任务的微调。研究者在三个下游语料库上测试:OpenWebText(网页文本,约90亿token)、OpenWebMath(数学文本,约40亿token)和CodeParrot(代码,约130亿token),在所有三个领域都观察到了持续改善。
推理基准测试的收益同样可见。GSM8K数学推理测试中,NCA预训练将pass@1从3.8%提升到4.4%;HumanEval代码生成测试中,pass@1从6.8%提升到7.5%;BigBench-Lite综合推理测试中,pass@4从25.9%跃升至36.5%。这些绝对数字不算大,毕竟这些是16亿参数的模型,而非千亿级的商用系统,但对照实验的一致性指向了一个清晰信号:从非语言数据中习得的某些东西,确实在帮助模型处理语言任务。
拆解:注意力层与MLP层的功能分工
研究者做了拆解实验:NCA预训练完成后,选择性重新初始化模型不同组件,然后观察下游表现变化。结果非常明确:重新初始化注意力权重造成的性能损失最大,远超其他组件。这意味着注意力层承载了最多的可迁移结构。
MLP层的效果则因领域而异。在OpenWebText上,保留NCA阶段的MLP权重反而会干扰语言学习;但在CodeParrot上,影响可以忽略不计。这一发现和Jelassi等人(2025年)对混合专家(MoE)架构的分析形成呼应,那项工作表明扩大MLP参数主要增强的是记忆能力而非推理能力。
两相对照,功能分工的图景浮现出来:注意力层负责学习通用的依赖追踪和上下文推断机制,MLP层则倾向于存储特定领域的模式和统计规律。正因如此,注意力层从NCA到语言的迁移是万金油式的,而MLP的迁移效果取决于源域和目标域之间的匹配程度。
关键:复杂性匹配决定迁移效果
研究中使用gzip压缩率作为NCA轨迹复杂性的度量,压缩率低意味着数据更有规律、更可预测,压缩率高则意味着更丰富的时空结构。把NCA数据按压缩率分成几个区间(20-30%、30-40%、40-50%、50%以上),分别测试各区间对不同下游领域的迁移效果。
结果表明,网页文本和数学文本从高复杂度NCA(50%+压缩率)中受益最大,而代码领域的最优区间在中等复杂度(30-40%)。这恰好与目标语料自身的复杂度特征对齐,OpenWebText和OpenWebMath的gzip压缩率在60-70%,CodeParrot则只有32%。这意味着合成数据不是越多越好或越复杂越好,而是需要与目标领域的计算特征相匹配。研究者称之为domain-targeteddatadesign,一种自然语言训练中不存在的调控杠杆。
理论:柏拉图表征假说与Epiplexity概念
这项工作的理论背景可以追溯到几条学术脉络。一条是MITPhillipIsola团队在2024年提出的柏拉图表征假说(PlatonicRepresentationHypothesis),核心观点是不同模态、不同架构的AI模型,随着规模增大,内部表征正在趋同,仿佛都在逼近对现实世界的某种共同统计模型。如果这个假说成立,那么从非语言数据中能学到与语言相通的表征,就不那么令人惊讶了。
另一条脉络来自Finzi等人(2026年)提出的epiplexity概念,它指出对于计算能力有限的观察者而言,简单的确定性过程也能生成需要学习才能把握的结构信息。经典信息论认为确定性变换不能增加信息量,但那假设的是全知全能的观察者;对于一个有限容量的transformer来说,生命游戏中涌现的滑翔机和碰撞图案,确实包含了它必须理解才能预测的东西。
解释:为何少量自动机数据胜过海量英语文本
关于为什么1.6亿token的自动机数据能胜过16亿token的英语,研究者给出的解释是:在远低于计算最优规模的token预算下(Chinchilla定律建议16亿参数模型需要约320亿token),自然语言训练主要在学习浅层的局部模式,比如词汇搭配、句法片段这些表面功夫。
NCA数据由于每条序列都对应一个独特的动力学规则,多样性极高,冗余性极低,每个token都在训练模型做深层的规则推断。Abbas等人(2023年)的研究已经表明大规模自然语言数据集内部存在大量语义冗余,NCA在token效率上的优势就变得可以理解了。
局限与展望:规模化挑战与未来方向
目前实验规模限于16亿参数,距离工业级千亿参数模型还有数量级的差距。NCA预训练的增益随模型规模增大而递减,400M模型改善了8.6%,1.6B模型改善了5.7%,这个趋势在更大规模上是否会完全消失,目前还不清楚。此外,对于较大字母表(n=10,15)的NCA,收益在一定token预算后出现饱和甚至下降,说明简单地生成更多NCA数据并不是万能解法。
但研究者的期望不止于此。论文结尾写道,最终愿景是完全用干净的合成数据做预训练,只在最后阶段用少量经过精心筛选的自然语言来获取语义。当前的pre-pre-training框架是这个范式的早期原型。